



呜啦!日常碎碎念,偶尔掉落优质前端博文推荐、学习资源等
网页:https://tg.cosine.ren
本频道的搜索Bot 来辣 👉 @cosSearchBot
私聊直接发消息就可以搜索啦~
🔖tags
#优质博文 #资源推荐 #博客更新 #碎碎念 #项目更新 #手工 #书摘 #阮一峰的科技周刊 #新动态
图频:Cosine 🎨 Gallery @CosineGallery
猫片: @cosine_cat
联系频道主:@cosine_yu
网页:https://tg.cosine.ren
本频道的搜索Bot 来辣 👉 @cosSearchBot
私聊直接发消息就可以搜索啦~
🔖tags
#优质博文 #资源推荐 #博客更新 #碎碎念 #项目更新 #手工 #书摘 #阮一峰的科技周刊 #新动态
图频:Cosine 🎨 Gallery @CosineGallery
猫片: @cosine_cat
联系频道主:@cosine_yu
#优质博文 #AI #前端 #开源
agentation:一款为 AI Agents 设计的视觉反馈工具,通过点击并添加标注,随后生成包含元素路径、CSS 选择器(Selectors)、位置等详细上下文的 Markdown 文本。
文档:https://agentation.dev/
Tweet:Introducing Agentation: a visual feedback tool for agents
agentation:一款为 AI Agents 设计的视觉反馈工具,通过点击并添加标注,随后生成包含元素路径、CSS 选择器(Selectors)、位置等详细上下文的 Markdown 文本。
文档:https://agentation.dev/
Tweet:Introducing Agentation: a visual feedback tool for agents
AI 摘要:Benji Taylor 发布的 Agentation 是一款创新的开源视觉反馈工具,旨在解决开发者向 AI 描述 UI 问题时的沟通障碍。通过 npm i agentation 即可集成,它允许用户直接在网页上点击元素并添加标注,随后生成包含元素路径、CSS 选择器(Selectors)、位置等详细上下文的 Markdown 文本。
#优质博文 #AI #独立开发
不会编程的人能靠 AI 独立开发应用吗?
作者认为,AI 确实大幅降低了“将想法翻译成代码”的技术门槛,但“不会编程”、“靠 AI”和“应用”这些词语的边界远比想象中模糊。在与 AI 协作的过程中,使用者会不自觉地习得编程概念,AI 更多是作为博学但死板的“徒弟”或“翻译官”,帮助有逻辑、有想法的人实现愿景,而非代替思考和定义问题。
author So!azy
不会编程的人能靠 AI 独立开发应用吗?
作者认为,AI 确实大幅降低了“将想法翻译成代码”的技术门槛,但“不会编程”、“靠 AI”和“应用”这些词语的边界远比想象中模糊。在与 AI 协作的过程中,使用者会不自觉地习得编程概念,AI 更多是作为博学但死板的“徒弟”或“翻译官”,帮助有逻辑、有想法的人实现愿景,而非代替思考和定义问题。
author So!azy
#优质博文 #AI #开源 #Ollama
当安全团队因合规性禁用云端 AI 工具(如 Cursor / Claude Code)时,OpenCode 配合 Ollama 可提供了本地运行的替代方案,这篇文章简要介绍了一下。
虽然我没有这种烦恼,但是 mark 一下。
Your security team blocked Cursor and Claude Code—time to switch to OpenCode
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
author Ikeh Akinyemi
当安全团队因合规性禁用云端 AI 工具(如 Cursor / Claude Code)时,OpenCode 配合 Ollama 可提供了本地运行的替代方案,这篇文章简要介绍了一下。
虽然我没有这种烦恼,但是 mark 一下。
Your security team blocked Cursor and Claude Code—time to switch to OpenCode
AI 摘要:文章介绍了 OpenCode,这是一个支持本地 LLM(大语言模型)运行的开源 AI 编程助手。针对医疗、金融等对数据主权(Data Sovereignty)要求严苛的行业,OpenCode 通过集成 Ollama,确保代码不离开本地机器,从而规避了 Cursor 和 Claude Code 等云端工具带来的合规风险。虽然本地模型在逻辑推理和复杂调试上目前仍逊于云端模型,但在严格监管的环境下,它是目前最可行的 AI 辅助开发方案。
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
1. 合规挑战与解决方案
• 多数云端 AI 工具(AI coding tools)会将代码片段发送至第三方服务器,这违反了医疗(PHI)、金融(SOC 2)或政府行业的合规要求。
• OpenCode 作为开源替代方案,通过支持本地模型运行(Local model execution)确保数据隐私。
• 虽然本地模型在质量上不一定优于 Cursor,但在云端工具被封锁时,它是唯一的合规选择。
2. OpenCode 技术架构与配置
• OpenCode 提供终端 TUI(Text user interface)、VS Code 扩展和桌面应用。
• 核心功能是通过 Ollama 充当本地编排器,支持 Qwen 2.5 Coder 和 DeepSeek Coder 等模型。
• 需要手动调整上下文窗口(Context window)配置,默认的 4,096 token 往往不足以处理多文件编辑,建议提升至 16K–32K。
3. 性能评测与实战表现
• 代码重构(Refactoring):本地模型需要更多的人工干预和显式指令(Explicit instructions),难以一次性完成高质量重构。
• 模式匹配(Pattern-matching):在编写输入验证(Input validation)等标准任务时表现出色,能自动匹配项目规范。
• 复杂调试(Debugging):在处理跨文件或涉及系统底层逻辑(如时区处理)的 Bug 时,本地模型容易出现幻觉(Hallucinations)并失败。
4. 行业应用场景建议
• 适用场景:医疗保健、金融机构和政府承包商,这些行业无法签署供应商的免责协议。
• 权衡取舍:选择本地模式意味着放弃了云端模型(如 Claude Sonnet 4)的高速度和深度架构理解能力,需要预留 2-3 倍的开发时间。
• 结论:如果条件允许,首选 Cursor;如果出于合规性必须本地化,OpenCode 是目前的最佳实践。
author Ikeh Akinyemi

#优质博文 #CMS #Sanity #AI
"You should never build a CMS" | Sanity:Sanity 回应 Cursor 将 CMS 迁移至 Markdown 的热议,分享了许多非常好的使用 CMS 的理由。
感觉这个确实:
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
"You should never build a CMS" | Sanity:Sanity 回应 Cursor 将 CMS 迁移至 Markdown 的热议,分享了许多非常好的使用 CMS 的理由。
感觉这个确实:
当同一条信息(如价格、法律条文)出现在多个地方时,Markdown 需要手动更新多处,而结构化内容只需修改一处。
AI 摘要:这篇文章是 Sanity 官方对 Lee Robinson(Cursor 团队)近期将内容从 CMS 迁移到 Markdown 文件这一趋势的深度回应。作者承认了传统 Headless CMS(无头内容管理系统)在复杂性、身份验证和 AI 接入方面的痛点,但指出“删除 CMS 并不等于删除了管理需求”。文章强调 Markdown 方案在处理非规范化数据、复杂语义协作和高级查询(Grep 的局限性)方面存在天然缺陷。Sanity 认为,真正的解法不是退回到原始的扁平文件,而是利用如 MCP(Model Context Protocol,模型上下文协议)等新技术,让 AI 直接与结构化内容 API 交互,构建真正面向 AI 的内容基础设施。
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
1. 现状反思:为何开发者想要逃离 CMS
• 承认 Headless CMS 带来的复杂性并没有为所有用户提供成比例的价值。
• 痛点分析:笨重的预览工作流(Preview workflows)、碎片化的身份验证(Auth fragmentation)以及高昂的存储成本。
• AI 接入障碍:传统的 API 验证屏蔽了 AI Agent,使其无法像读取本地代码库一样轻松访问 CMS 内容。
2. 核心争论:Markdown 的“内容即页面”陷阱
• 简单性的错觉:Markdown 适合一对一的简单页面,但无法处理内容的规范化(Normalization)。
• 维护噩梦:当同一条信息(如价格、法律条文)出现在多个地方时,Markdown 需要手动更新多处,而结构化内容只需修改一处。
• 实体与字符串:Markdown 本质上是字符串的堆砌,缺乏实体(Entities)概念,难以进行复杂的关联分析。
3. 工具边界:Git 与内容协作的错位
• 合并冲突的本质:代码合并是结构化的(Mechanical),而内容合并是语义化的(Semantic),Git 无法理解内容修改的意图。
• 实时协作需求:内容团队通常需要实时反馈,而非 Git 式的异步提交与拉取。
• 扩展性瓶颈:随着内容规模增长,Git 方案往往会演变成需要通过 Slack 协调修改或复杂的 PR 审核流程。
4. 技术深潜:Grep 无法替代结构化查询
• 检索局限性:Grep(全局正则表达式搜索)只能做简单的模式匹配,无法处理逻辑复杂的查询(如“查询某日期后发布的所有企业类案例”)。
• 查询语言的力量:展示了 GROQ 语言在处理复杂数据筛选时的优势,强调结构化数据才是 AI Agent 推理的最佳底座。
5. 未来趋势:面向 AI 的内容基础设施
• MCP 服务器的兴起:介绍 Sanity 推出的 MCP 服务器,使 AI Agent 能直接操作内容模式(Schema)并管理发布。
• 格式误区:区分“适合 AI 输入输出的格式(Markdown)”与“适合作为基础设施的格式(结构化数据)”。
• 真正的 AI 驱动:内容应是可查询的(Queryable)而非仅可搜索的(Grep-able),且应与展示层无关(Presentation-agnostic)。


#碎碎念 #AI #杂谈
越用 AI 会越有种「啊他果然取代不了我」的感觉,尤其是他犯蠢的时候。
但是很多时候又很方便确确实实省下来了很多摸鱼时间,又爱又恨的感觉。
也不奇怪很多程序员会排斥 AI 写代码,因为架构上真的很容易犯蠢,写的代码但凡是个代码洁癖都会感觉哎呦还不如自己来写,但是重复性业务工作真的太省劲了。
虽然下沉市场和资本感觉都在 AI 狂欢,但我体感上的话,感觉其实平常程序员的生活是从写代码变成审计划和审代码改代码了,更爽了,写自己的东西更有劲了x
ai 真的容易堆屎山,我现在每次写完让 opus 4.5 review 一遍 codex review 一遍都差不多了我再看才能好点儿,不过他们自己 review 的效果还是挺好的。
PS: 仅限前端/ Swift 领域,后端我只能通过同事的使用感受推测
越用 AI 会越有种「啊他果然取代不了我」的感觉,尤其是他犯蠢的时候。
但是很多时候又很方便确确实实省下来了很多摸鱼时间,又爱又恨的感觉。
也不奇怪很多程序员会排斥 AI 写代码,因为架构上真的很容易犯蠢,写的代码但凡是个代码洁癖都会感觉哎呦还不如自己来写,但是重复性业务工作真的太省劲了。
虽然下沉市场和资本感觉都在 AI 狂欢,但我体感上的话,感觉其实平常程序员的生活是从写代码变成审计划和审代码改代码了,更爽了,写自己的东西更有劲了x
ai 真的容易堆屎山,我现在每次写完让 opus 4.5 review 一遍 codex review 一遍都差不多了我再看才能好点儿,不过他们自己 review 的效果还是挺好的。
PS: 仅限前端/ Swift 领域,后端我只能通过同事的使用感受推测
#tools #AI
The Agent Skills Directory
Vercel 公布了 skills.sh,是一个用于查找和共享代理技能的网站。
通过以下方式为任何代理添加技能:
Source
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
The Agent Skills Directory
Vercel 公布了 skills.sh,是一个用于查找和共享代理技能的网站。
通过以下方式为任何代理添加技能:
npx skills add <owner/repo>Source
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
1. 前端开发与主流框架最佳实践 (Frontend Development & Frameworks)
• Vercel & React 体系:包含 Vercel 官方推荐的 React 最佳实践和网页设计指南,是目前安装量最高的技能。
• Expo & React Native:涵盖了 Expo 框架的升级、UI 构建、数据获取、CI/CD 流程以及原生 UI 开发等全方位技能。
• Vue & Nuxt 生态:提供了 Nuxt 模块开发、Nuxt UI 使用、Motion 动画库集成以及针对 Vue 的专项支持。
• 3D 与可视化:如 Three.js 的动画、材质、着色器 (Shaders) 和光照等进阶开发技能。
2. AI 智能体元能力与 MCP 集成 (AI Agent Meta-skills & MCP)
• 技能创建工具:Anthropic 提供的 skill-creator 和 mcp-builder(模型上下文协议构建器),帮助开发者快速为 AI 编写新技能。
• 智能体架构:包括子智能体驱动开发 (Subagent-driven development)、并行智能体分发 (Dispatching parallel agents) 以及智能体开发框架。
• 平台集成:如 OpenRouter TypeScript SDK 集成、Stripe 最佳实践、Slack GIF 创建器等。
3. 安全、测试与底层审计 (Security, Testing & Code Audit)
• 漏洞扫描:由 Trail of Bits 提供的各类区块链(Solana, Substrate, TON, Cairo)漏洞扫描器。
• 模糊测试 (Fuzzing):集成了 libFuzzer、AFL++、OSS-Fuzz 和 Atheris 等多种自动化测试工具。
• 代码质量保障:包含系统化调试 (Systematic debugging)、测试驱动开发 (TDD)、代码复查 (Code Review) 和代码成熟度评估。
4. 市场行销、内容创作与生产力 (Marketing, Content & Productivity)
• 营销自动化:涵盖 SEO 审计、文案编辑 (Copywriting)、定价策略、营销心理学以及落地页转化率优化 (CRO)。
• 多媒体与社交媒体:针对小红书 (XHS)、X (Twitter) 的图片和帖子生成工具,以及漫画、信息图表 (Infographic) 的创作技能。
• 办公文档处理:支持对 PDF、XLSX、DOCX、PPTX 等复杂文件格式的深度解析与处理。
• 知识管理:针对 Obsidian 的 Markdown 增强、JSON Canvas 以及基础库配置。
5. 开发者工具与自动化 (DevTools & Automation)
• Git 与工作流:如使用 Git Worktrees、处理开发分支、自动生成变更日志 (Changelog) 等。
• 认证与后端:Better Auth 的最佳实践及其在不同框架(如 Nuxt)中的集成。
• 数据库与云服务:Convex 框架的各种功能实现,如实时数据、函数调用、模式验证器 (Schema validator) 等。

#优质博文 #Markdown #技术文化 #AI #软件工程
How Markdown took over the world:回顾 Markdown 的诞生历程及其如何从一个小众博客工具演变为统治现代互联网和 AI 交互的通用文本标准。
author Anil Dash
How Markdown took over the world:回顾 Markdown 的诞生历程及其如何从一个小众博客工具演变为统治现代互联网和 AI 交互的通用文本标准。
AI 摘要:这篇文章由资深科技人 Anil Dash 撰写,深入探讨了 Markdown 这一简单纯文本格式如何从 2004 年的一个个人项目,演变成如今统治全球科技行业的标准。它由 John Gruber 创立,并由天才少年 Aaron Swartz 协助测试。Markdown 的成功不仅在于其技术上的简洁(易读、易写、基于现有邮件习惯),更在于其开源和去中心化的精神。文章指出,即使是当今最尖端的 AI 系统(如 ChatGPT 和 Claude),其核心交互和指令也高度依赖 Markdown。这种由个人创造并免费赠予世界的工具,证明了互联网的进步往往源于普通人的慷慨与对细节的执着,而非仅由科技巨头推动。
author Anil Dash
#优质博文 #React #LLM #前端 #AI #逆向工程
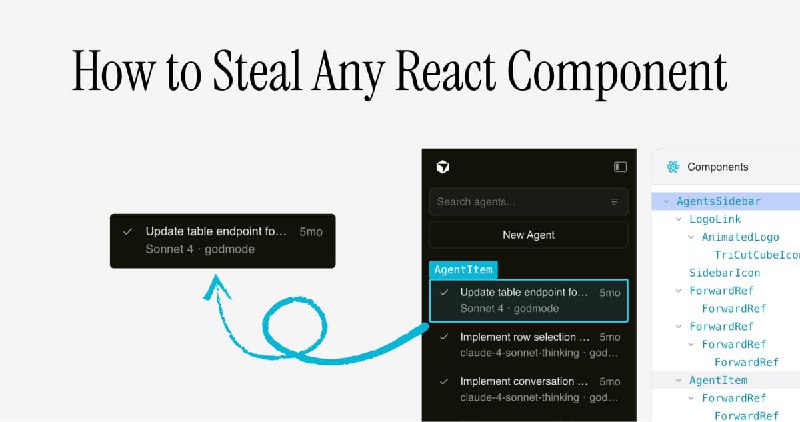
How to Steal Any React Component
网页做的还挺有趣的,介绍如何使用 React 的内部数据结构(通过 Fiber)和 LLM 来重建生产 React 应用程序中的组件,而无需原始源代码。
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
How to Steal Any React Component
网页做的还挺有趣的,介绍如何使用 React 的内部数据结构(通过 Fiber)和 LLM 来重建生产 React 应用程序中的组件,而无需原始源代码。
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
1. 核心原理:理解浏览器中的两棵树
• DOM 树:浏览器渲染的 HTML 结构,可以通过开发者工具查看。
• React Fiber 树:React 维护的内部结构,记录了组件层次、属性 (Props) 和状态 (State)。
• 切入点:从 React 16 开始,React 将 Fiber 节点挂载在 DOM 元素上,通过遍历 DOM 即可获取组件的内部信息。
2. 数据采集:建立属性与输出的映射
• 组件归类:利用 Fiber 节点的 type 属性(内存引用)识别相同类型的组件。
• 样本收集:记录同一个组件在不同 Props 下产生的不同 HTML 输出,为 LLM 提供训练样本。
• 获取源码线索:通过 type.toString() 提取混淆后的源代码,辅助 LLM 理解业务逻辑。
3. 组件重建:LLM 与自动化验证
• LLM 提示词:向模型提供 Props 示例、HTML 输出和压缩后的源码,要求其写出干净的 React 代码。
• 验证循环 (Verification Loop):自动渲染 LLM 生成的组件,对比其 HTML 输出与原站点的差异,并根据 Diff 反馈给 LLM 进行修复。
4. 组装策略:拓扑排序与局限性
• 拓扑排序 (Topological Sort):根据依赖关系,先还原最底层的叶子组件(如 Button、Avatar),再逐步向上还原复杂的父组件(如 LoginForm)。
• 处理失效情况:针对 JS 动画导致的 DOM 状态不匹配或复杂的内部交互状态,如果 LLM 无法还原,则退而求其次使用 HTML 快照 (Snapshot)。
• 最终集成:将还原的组件与 CSS、静态资源 (Assets) 整合,构建出功能完整的 React 项目
#AI #React #前端 #性能优化
vercel 开源了他们写 react 以及各种情况下的用到的 skill(
通过
vercel-labs/agent-skills
vercel 开源了他们写 react 以及各种情况下的用到的 skill(
通过
npx add-skill vercel-labs/agent-skills 安装vercel-labs/agent-skills
AI 摘要:vercel-labs/agent-skills 是一个 GitHub 仓库,汇集了专为 AI 编程代理(AI Coding Agents)设计的“技能”(Skills)。这些技能通过预打包的指令和脚本,增强了代理在代码开发、审查和部署方面的能力。目前包含 react-best-practices(专注于 React/Next.js 性能优化)、web-design-guidelines(审查 UI 代码的无障碍性、性能和用户体验)以及 vercel-deploy-claimable(快速将应用部署到 Vercel)等核心技能。通过简单的命令行安装后,AI 代理可自动识别并利用这些技能来完成相关任务,极大地提升了自动化开发和部署的效率。
#优质博文 #前端 #AI #React #debug
AI 无意中在应用程序中引入了一个隐藏的、导致浏览器崩溃的无限 React 组件树,而 React 19 的
AI 编码代理如何隐藏了应用程序中的定时炸弹
author Andrew Patton
AI 无意中在应用程序中引入了一个隐藏的、导致浏览器崩溃的无限 React 组件树,而 React 19 的
<Activity> 组件则巧妙地掩盖了这个问题。AI 编码代理如何隐藏了应用程序中的定时炸弹
AI 摘要:本文讲述了作者在使用 AI 编码代理开发 Outlyne(一个 AI 驱动的网站构建器)过程中,遭遇的一个由 AI 代理错误删除注释后引发的隐藏 bug。该 bug 导致应用程序中出现了无限的 React 组件递归渲染,并通过 React 19 的 <Activity> 组件巧妙地隐藏起来,直到用户浏览器因内存耗尽而崩溃。作者通过深入调试,最终找到了问题的根源,并强调了将关键代码约束(structural invariants)转化为自动化测试的重要性,而非仅仅依赖注释。
author Andrew Patton
https://www.ui-skills.com/
miantiao/2010191460188995854
Zola Chat 和 prompt-kit 作者 @Ibelick 沉淀了他使用 Tailwind + shadcn-ui 生态(Base UI)+ framer-motion 进行 AI 编程时的 Skill , 用来约束 AI 过度设计和给出明确的设计方向。
或许每个项目都应该又一个类似的 UI Skill 来约束项目的设计风格,我准备给项目也加一下
#tools #AI #代码搜索
React Scan 作者发布了新作品 Repogrep,一个由 AI 驱动的超快速代码库搜索工具,能够帮助开发者在公共 GitHub 仓库中查找代码,比较类似 DeepWiki,但是快,超级快。
React Scan 作者发布了新作品 Repogrep,一个由 AI 驱动的超快速代码库搜索工具,能够帮助开发者在公共 GitHub 仓库中查找代码,比较类似 DeepWiki,但是快,超级快。
Aiden Bai(aidenybai): 介绍 repogrep.com 对任何公共 GitHub 仓库进行超快速代码库搜索
我在不到 10 秒内找到了 React Hooks 的源代码。
https://x.com/aidenybai/status/2008222085240549530
AI 摘要:Repogrep 是一款创新的 AI 编码代理,专为解决在海量代码库中快速搜索的痛点而设计。它能够搜索任何公共 GitHub 仓库,用户只需粘贴 GitHub 仓库 URL 或输入关键词,即可实现超快的代码查找。
#优质博文 #css #可视化 #AI #前端 #新动态
经群友提醒想起来看到了这个,打不过就加入。
蚂蚁集团 AntV 团队推出新一代声明式信息图表(Infographic)生成与渲染框架,旨在通过 AI 驱动让数据叙事更简单。
GitHub: antvis/Infographic
官网: https://infographic.antv.vision/ai/
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
经群友提醒想起来看到了这个,打不过就加入。
蚂蚁集团 AntV 团队推出新一代声明式信息图表(Infographic)生成与渲染框架,旨在通过 AI 驱动让数据叙事更简单。
GitHub: antvis/Infographic
官网: https://infographic.antv.vision/ai/
AI 摘要:AntV Infographic 是一个专为 AI 时代设计的声明式信息图表渲染引擎。它采用简洁的声明式语法,支持 AI 流式输出(Streaming Output)与实时渲染,并内置了超过 200 种信息图表模板、组件和布局。该框架不仅提供高质量的 SVG 输出,还拥有丰富的主题系统(包括手绘风和渐变色)以及配套的在线编辑器,极大提升了信息展示的效率,让开发者和 AI 能够更轻松地创作专业级别的数据故事。
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
1. 核心特性(Core Features)
• AI 友好(AI-friendly):语法与配置专为 AI 生成进行了优化,提供简洁的提示词(Prompts),并支持 AI 流式输出的即时渲染。
• 开箱即用(Ready to use):内置约 200 个信息图表模板、数据项组件和布局方案,可快速构建专业作品。
• 主题系统(Theme system):支持手绘、渐变、图案等多种预设主题,并允许深度自定义。
• 内置编辑器(Built-in editor):提供可视化编辑器,方便对 AI 生成的结果进行二次微调。
• 高质量 SVG 输出:默认采用 SVG 渲染,确保视觉保真度且易于后期编辑。
2. 快速上手与集成(Installation & Quick Start)
• 通过 NPM 轻松安装:使用 npm install @antv/infographic 即可引入项目。
• 声明式语法:演示了如何通过简单的配置项和类 YAML 的文本语法快速渲染出一个带箭头的步骤列表图。
• 极简 API 设计:通过 new Infographic() 实例化并调用 render() 方法即可完成渲染。
3. 流式渲染技术(Streaming Rendering)
• 高容错语法:设计了具备高容错性的信息图表语法,即使在 AI 文本生成的过程中也能实时解析。
• 动态预览:支持将 AI 输出的每个片段(Chunks)实时渲染到界面上,提供丝滑的生成体验。
4. 社区动态与许可(Community & License)
• 社区交流:鼓励通过 GitHub Discussions 和 Issues 进行交流反馈。
• 开源协议:项目采用 MIT 协议开源。

#优质博文 #AI #LLM
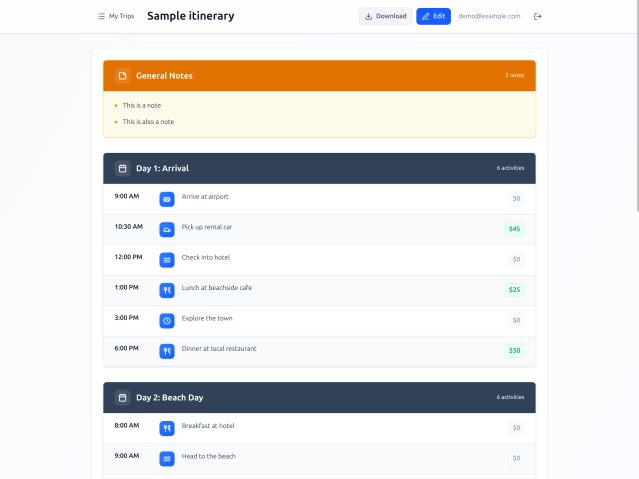
An experiment in vibe coding
author Nolan Lawson
An experiment in vibe coding
AI 摘要: 作者 Nolan Lawson 在假期挑战自己以 “vibe coding” (即尽量不亲自写代码、主要通过 LLM 助手生成)构建一个供妻子使用的旅行行程管理 Web 应用。项目利用 Claude Code、Tailwind CSS、React、PocketBase 与 Railway 进行快速开发,最终成果稳定且满足需求。但实践暴露出当前 LLM 编码工具的不足:非程序员难以高效运用、可访问性差、性能优化需要人工介入。作者反思 “vibe coding” 的局限,也看到其在轻量、个性化应用中的潜力,并对未来软件开发职业与 AI 协作形态表示复杂的期待与忧虑。
author Nolan Lawson
#优质博文 #AI #编程
好文,我也是这样转变的(?)或者说没有转变。
有趣的是 AI 出来之后我觉得编码热情或者说想构建产品的欲望越来越强烈了。
How I use AI agents to write code
[以下是方便搜索索引的大纲(AI 生成),请读原文]
author Nolan
好文,我也是这样转变的(?)或者说没有转变。
有趣的是 AI 出来之后我觉得编码热情或者说想构建产品的欲望越来越强烈了。
How I use AI agents to write code
AI 摘要:作者从一个“反 AI 狂热者”转变为 AI 代理的使用者,因为他发现 AI 在代码编写上的生产力惊人。他详细介绍了如何设置 AI 代理(以 Claude Code 为例),强调了配置清晰的 CLAUDE.md 文件(包括项目架构和个人编码习惯)的重要性。在整体策略上,他强调了结合自动化测试提供反馈循环,以及在复杂任务中使用“计划模式”来让 AI 进行思考。作者还分享了处理 AI 常见错误(如删除注释、代码重复)的方法,即开启新会话让 AI 进行“代码审查”。此外,他还提到 AI 代理能在夜间持续工作,实现“睡着也能完成额外工作”的优势。尽管作者对 AI 代理仍抱有复杂情感,认为它们剥夺了编程乐趣,但他承认 AI 显著提升了编码效率,将自己的角色比作软件架构师,主要负责设计和审查,而非亲手编写所有代码。
[以下是方便搜索索引的大纲(AI 生成),请读原文]
1. 对 AI 编码态度的转变
• 从“反 AI 狂热者”到接受者:作者承认尽管曾强烈反对 AI,但其同事的生产力提升以及 AI 工具(如 Claude Code、OpenAI Codex、Gemini CLI)的发布,使其无法再忽视。
• 承认 AI 的高效性:尽管作者有 20 年的编程经验和对代码质量的“老派”看法,但 AI 在许多时候比他写得更好。
• 强调正确使用 AI:将 AI 比作“锋利的菜刀与电锯的组合”,强调不当使用可能造成伤害。
2. AI 代理的基本设置
• 选择工具:作者主要使用 Claude Code,因其足够好用,虽然市面上有许多其他选择。
• CLAUDE.md 文件的作用:
• 项目级 CLAUDE.md:用于描述项目概况、整体架构、注意事项等,帮助 AI 理解代码库。
• 个人级 CLAUDE.md:记录个人编码习惯和偏好(例如:在 map() 或 filter() 函数中使用 _ 变量名)。
3. 整体使用策略
• 吸取教训:作者承认在 AI 上浪费了大量时间,AI 代理可能会“引你走弯路”,导致创建出“勉强能用”的“怪物”。
• 建立反馈循环:
• 自动化测试:通过自动化测试让 AI 代理验证其解决方案,纠正错误。
• “计划模式”(plan mode):对于复杂任务,让 AI 在执行前先“思考”并制定计划,可以有效避免盲目尝试。
• AI 在 UI 方面的局限性:AI 在处理 UI 任务时效率较低,因为需要消耗大量 token 进行 DOM 检查或通过截屏检查,导致速度缓慢且容易出错。
4. 处理 AI 产生的错误
• AI 常见的错误类型:
• 删除有用的注释:将重要信息移除或修改。
• 代码重复:AI 代理倾向于复制粘贴代码,违反 DRY (Don't Repeat Yourself) 原则。
• 引入细微的错误:在重构时无意中改变代码原意(例如:添加多余的空值检查)。
• 解决策略:
• 重启会话进行“代码审查”:开启新的 AI 会话,让其对比 origin/main 进行纯重构检查,并查找功能性错误。
• 伪装代码来源:为了获得更客观的反馈,可以谎称审查的是同事的 PR (Pull Request)。
• 重复检查:多次运行相同的审查流程,确保所有错误都被发现和修复。
5. AI 带来的额外价值
• “睡着也能完成额外工作”:AI 代理不知疲倦,可以持续迭代解决问题,为作者节省时间。
• “自动化盲区”(automation blindness)的风险:长时间对 AI 的输出无条件“同意”,可能导致忽视潜在问题。
• “yolo 模式”下的试验:在 Podman 容器中运行 AI 代理,以减少对人工干预的依赖,但作者仅在不重要的副项目中使用,以防潜在的安全问题。
• 工作与生活平衡的挑战:AI 可能导致工作侵入非工作时间,需警惕。
6. 结论与个人感受
• 复杂的情感:作者对 AI 代理仍抱有复杂甚至“厌恶”的情感,认为它们让编程变得不那么有趣,但其有效性是不可否认的。
• 效率的巨大提升:AI 极大地提高了代码编写速度。
• 适用场景:AI 不适合处理复杂、新颖或涉及代码库多个分散部分的模糊项目,这类任务仍需人工完成。
• 角色转变:作者将自己的新角色比作软件架构师,更多地参与规范编写和代码审查,而非纯粹的编码。
• 对开源项目的影响:作者在开源项目中不使用 AI,因为缺乏“所有权”感,认为代码不是自己亲手写的。
• “不那么有趣,但最优”的选择:尽管 AI 让编程乐趣减少,但它作为“最优策略”,仍会被选择使用,就像游戏中玩家会选择最有效率而非最有趣的玩法。
• 接受现状:作者认为大多数开发者已经接受 AI,并正在向前发展。
author Nolan
#优质博文 #AI #前端 #React #调试
How AI Coding Agents Hid a Timebomb in Our App
以下是方便搜索索引的大纲(AI 生成),请读原文
author Andrew Patton
How AI Coding Agents Hid a Timebomb in Our App
AI 摘要: 作者分享了他们在开发 Outlyne 这款 AI 驱动的网站构建器时遇到的一个诡异 Bug:一个由 AI 编程助手(AI Coding Agent)删除的代码注释,导致一个关键的 readOnly 属性被移除,进而引发了 React 组件的无限递归渲染。更糟的是,React 19 的 <Activity> 组件将这个 Bug 隐藏了起来,使其在数分钟内都不会崩溃,极大增加了调试难度。作者通过痛苦的调试过程,最终发现罪魁祸首是 AI 删除了注释,以及自己没有为关键的结构性约束编写测试。文章强调了在 AI 辅助开发背景下,测试而非注释,才是确保代码质量和安全的关键。
以下是方便搜索索引的大纲(AI 生成),请读原文
1. Bug 的出现与表现
• 应用程序崩溃:用户在使用应用时,浏览器会无故冻结并崩溃。
• 内存无限增长:后台一个无限递归的 React 组件树在内存中不断增长,最终耗尽内存。
• React 19 的 <Activity> 组件掩盖了问题:新引入的 <Activity> 组件在关闭状态下会以低优先级模式渲染隐藏的 UI,导致无限递归的组件树在后台缓慢构建,而前端页面保持响应,延迟了 Bug 的暴露时间。
2. 问题根源:AI 编程助手与被删除的注释
• Outlyne 的组件架构:页面组件包含头部(header)和底部(footer),它们渲染了自身的变体(variants)作为预览,这本身就是递归的。为了避免无限递归,预览组件设置了 readOnly={true} 属性。
• 重要的安全注释:作者曾添加注释警告,如果 readOnly 属性为 false 会导致无限递归。
• AI 编程助手的操作:在一次重构中,AI 编程助手删除了这个关键注释,可能是出于“清理”目的。
• readOnly 属性被移除:在后续的更新中,由于缺乏注释的上下文,AI 编程助手移除了 readOnly 属性,导致了无限递归的发生。
3. 艰难的调试过程
• 难以复现:Bug 不会立即崩溃,使得调查非常困难,应用在几分钟后才会崩溃。
• 虚假线索:Chrome 调试器显示问题出在 Motion 库中,作者花费数天时间调查,但发现 Motion 只是受害者。
• 关键突破:通过检查内存溢出时的调用栈,发现了与页脚编辑器相关的 layoutId,并最终通过移除 <Activity> 组件,使 Bug 立即暴露,确认了问题所在。
4. 经验教训与启示
• 注释与测试:注释是文档,而测试是约束。在 AI 辅助的代码库中,仅仅依靠注释不足以保证关键结构性约束。
• AI 辅助开发带来的挑战:AI 编程助手能够提高生产力,但它们也会无意中移除关键信息,这要求开发者重新思考“足够好”的代码标准。
• 重要的结构性约束需要测试:文章强调,任何可能导致应用崩溃或违反结构性不变性的地方,都应该编写测试来强制执行,而不是仅仅依靠注释。
• 示例测试代码:作者提供了一段简单的测试代码,说明如何用大约 20 行代码来断言 readOnly 属性的正确性,从而避免了整个 Bug。
author Andrew Patton
#优质博文 #前端 #CSS #AI #MCP #debug
这个好啊,Chrome DevTools MCP 终于能直接介入浏览器调试了。
Let your Coding Agent debug your browser session with Chrome DevTools MCP
以下是方便搜索索引的大纲(AI 生成),请读原文
author Sebastian Benz
这个好啊,Chrome DevTools MCP 终于能直接介入浏览器调试了。
Let your Coding Agent debug your browser session with Chrome DevTools MCP
AI 摘要:Chrome DevTools MCP 迎来了重大更新,现在允许 AI 编程助手直接连接到活跃的浏览器会话。这项新功能极大地提升了调试效率,编程助手可以重用现有登录会话、访问活跃的调试面板(如网络面板和元素面板),从而实现手动调试与 AI 辅助调试的无缝切换。文章详细介绍了这一功能的实现原理、安全措施(如用户授权弹窗和控制横幅)以及如何配置和使用,为开发者提供了更智能、更便捷的调试体验。
以下是方便搜索索引的大纲(AI 生成),请读原文
1. Chrome DevTools MCP 新功能概述
• 核心更新:Chrome DevTools MCP 服务器现在支持 AI 编程助手直接连接到活跃的浏览器会话。
• 主要优势
• 重用现有浏览器会话:编程助手可以直接访问已登录的会话,无需重新登录。
• 访问活跃调试会话:编程助手可以直接从 DevTools UI 访问并调查选定的元素或网络请求。
• 工作流改进:实现手动调试与 AI 辅助调试的无缝切换。
2. Chrome DevTools MCP 连接方式
• 现有连接方式
• 使用特定用户配置文件运行 Chrome。
• 通过远程调试端口连接到运行中的 Chrome 实例。
• 在独立临时配置文件中运行多个 Chrome 实例。
• 新增自动连接功能:通过 --autoConnect 选项,MCP 服务器可以请求远程调试连接。
3. 远程调试工作原理及安全措施
• 基础机制:基于 Chrome 现有的远程调试能力。
• 启用步骤:用户需在 chrome://inspect#remote-debugging 中手动启用远程调试。
• 连接流程:
• MCP 服务器配置 --autoConnect 选项后,将尝试连接活跃的 Chrome 实例。
• 用户授权:Chrome 会弹出对话框,要求用户授权远程调试会话,以防止滥用。
• 状态提示:调试会话激活时,Chrome 顶部会显示“Chrome is being controlled by automated test software”横幅。
4. 如何开始使用
• 步骤一:在 Chrome 中设置远程调试
• 导航至 chrome://inspect/#remote-debugging。
• 根据对话框提示允许或禁止传入的调试连接。
• 步骤二:配置 Chrome DevTools MCP 服务器
• 在 MCP 服务器配置中,为 chrome-devtools 服务添加 --autoConnect 命令行参数。
• 示例配置适用于 gemini-cli。
• 步骤三:测试设置
• 运行 gemini-cli 并输入性能检查指令。
• 允许 Chrome 弹窗中的远程调试请求。
• 验证 MCP 服务器是否能成功打开网页并执行性能追踪。
• 更多信息:可参考 GitHub 上的 README 文档获取完整说明。
5. 未来展望
• 调试任务交接:AI 编程助手可以接管调试任务,提升效率。
• 面板数据暴露:计划逐步向编程助手暴露更多 DevTools 面板数据。
author Sebastian Benz
