#优质博文 #React #LLM #前端 #AI #逆向工程
How to Steal Any React Component
网页做的还挺有趣的,介绍如何使用 React 的内部数据结构(通过 Fiber)和 LLM 来重建生产 React 应用程序中的组件,而无需原始源代码。
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
How to Steal Any React Component
网页做的还挺有趣的,介绍如何使用 React 的内部数据结构(通过 Fiber)和 LLM 来重建生产 React 应用程序中的组件,而无需原始源代码。
[以下是方便搜索索引的大纲 (AI 生成),请读原文]
1. 核心原理:理解浏览器中的两棵树
• DOM 树:浏览器渲染的 HTML 结构,可以通过开发者工具查看。
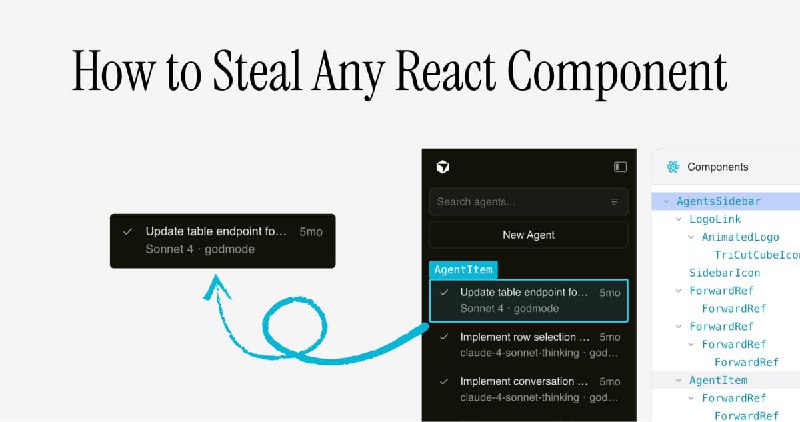
• React Fiber 树:React 维护的内部结构,记录了组件层次、属性 (Props) 和状态 (State)。
• 切入点:从 React 16 开始,React 将 Fiber 节点挂载在 DOM 元素上,通过遍历 DOM 即可获取组件的内部信息。
2. 数据采集:建立属性与输出的映射
• 组件归类:利用 Fiber 节点的 type 属性(内存引用)识别相同类型的组件。
• 样本收集:记录同一个组件在不同 Props 下产生的不同 HTML 输出,为 LLM 提供训练样本。
• 获取源码线索:通过 type.toString() 提取混淆后的源代码,辅助 LLM 理解业务逻辑。
3. 组件重建:LLM 与自动化验证
• LLM 提示词:向模型提供 Props 示例、HTML 输出和压缩后的源码,要求其写出干净的 React 代码。
• 验证循环 (Verification Loop):自动渲染 LLM 生成的组件,对比其 HTML 输出与原站点的差异,并根据 Diff 反馈给 LLM 进行修复。
4. 组装策略:拓扑排序与局限性
• 拓扑排序 (Topological Sort):根据依赖关系,先还原最底层的叶子组件(如 Button、Avatar),再逐步向上还原复杂的父组件(如 LoginForm)。
• 处理失效情况:针对 JS 动画导致的 DOM 状态不匹配或复杂的内部交互状态,如果 LLM 无法还原,则退而求其次使用 HTML 快照 (Snapshot)。
• 最终集成:将还原的组件与 CSS、静态资源 (Assets) 整合,构建出功能完整的 React 项目